I would like to groupby 2 columns of a big table in order to get a histogram / count for the combination. The table is a bit large, so when I choose to groupby the two columns in the dashboard it crashes (even when I filter the presented columns to 3 colmns, as requested)
2 possible directions I thought to go:
- Filtering by the search expression the columns. For instance
runs.summary["table"][["c1","c2","c3"]]
This is throwing a syntax error, and I could not find a proper syntax to choose multiple columns at once to present from a large table.
- Keep in that direction groupby
but to groupby multiple values.
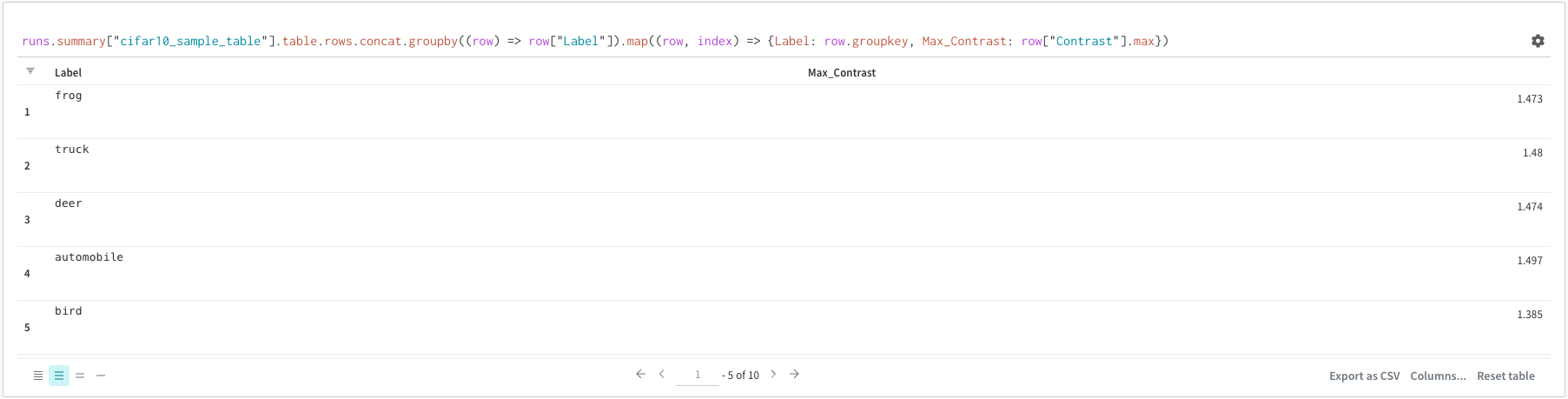
Again, it worked well for a single column
runs.summary[“all_predictions”].table.rows.concat.groupby((row) => row[“c1”]).map((row, index) => {c1: row.groupkey, c2: row.groupkey, c3: row.groupkey, count: row.count}).
but it not showing all the combinations (I guess it’s only grouping the first column, and taking the first value of the other columns)
What do you suggest me to do?
p.s I would like to keep this as a dashboard / table / list but not as artifact query, since It’s supposed to be eventually within one of my reports. You may assume the run set is frozen (so that would not be too heavy)
Thanks!
Hi @tankwell. Thank you for reaching out with your question.
Would you mind sharing the URL for the Workspace and the table you are trying to groupby 2 columns for us to have a look at and investigate?
A query like the following:
runs.summary["table_name"].table.rows.concat.groupby((row) => {"c1": row["c1"], "c2": row["c2"]}).map((row, index) => {c1: row.groupkey["c1"], c2: row.groupkey["c2"], c3_count row["c3"].count})
replacing c1,c2,c3 with your columns names should render the table you are looking for.
Thanks!
I do get a running query, but I think that not exactly what I was looking for.
the general purpose was to go over all the possible combinations
and to show it as a paged table accross runs or to present the avg. counts across all runs.
The table is a bit heavy, so I thought that by explicitly typing the query and not using the ‘group_by’ option would be more efficient
Hi @tankwell , having a look a the table you shared , you should be able to re-created directly typing the following query:
runs.summary["all_predictions"].table.rows.concat.groupby((row) => {is_the_person_drinking_pred: row["is_the_person_drinking_pred"], is_the_person_eating_pred: row["is_the_person_eating_pred"], is_drinking_bool: row["is_drinking_bool"]}).map((row, index) => {is_the_person_drinking_pred: row.groupkey["is_the_person_drinking_pred"], is_the_person_eating_pred: row.groupkey["is_the_person_eating_pred"],is_drinking_bool: row.groupkey["is_drinking_bool"], Count: row["is_drinking_bool"].count})
The table may still take a couple of seconds to load depending on how many Runs you have selected.
Thanks!
Now I get the overall count and not paged table with the correct count
Hi @tankwell , would you be able to share a screenshot of the table you are getting or a URL to a saved view with both the tables configured?
Are the same Runs being selected in the Workspace (if more than 100 Runs are visualised, only data from 100 of them will be queried for the table)?
Hi @tankwell , I wanted to follow up on this request. Please let us know if we can be of further assistance or if your issue has been resolved.
The issue was resolved with the map + count
I think that the issue was that my original query attempts were not very good
Thanks for supplying the right way to do it!

Great to hear this is now working as you intended! I will mark this as solved, please feel free to reach out in the future for any further questions.

{kind=link}